Research Data Management to facilitate Machine Learning
Motivation
With the advent of a paradigm shift towards data-driven scientific discovery in materials science and engineering (MSE), machine learning (ML) methods are increasingly finding their way into research domains that have previously relied on experimental discoveries aided by modeling and simulations. With the aid of ML models, properties of new materials can be predicted based on information that is too complex and too vast for traditional human reasoning. However, to make accurate predictions, ML methods rely on an adequately large volume of standardized and unbiased datasets for training and testing. Compared to other scientific domains, publicly available MSE datasets are heterogenous in nature and sparse in number.The systematic extraction of informative features from raw data to use as input for an ML algorithm (feature engineering) requires consistent and standardized data formats that are described with rich metadata. Accordingly, the acquisition, preprocessing, and quality control of data (often combined from heterogeneous data sources) is both a critical and a time-intensive step in building an ML model, particularly in the MSE domain. The high cost and time required for, e.g., the experimental synthesis of new materials and the characterization and optimization of their properties often precludes the generation of a sufficiently large volume of new data by single research groups or even institutions, highlighting the need for the development of common data standards and infrastructures for the sharing of MSE datasets.
Objectives
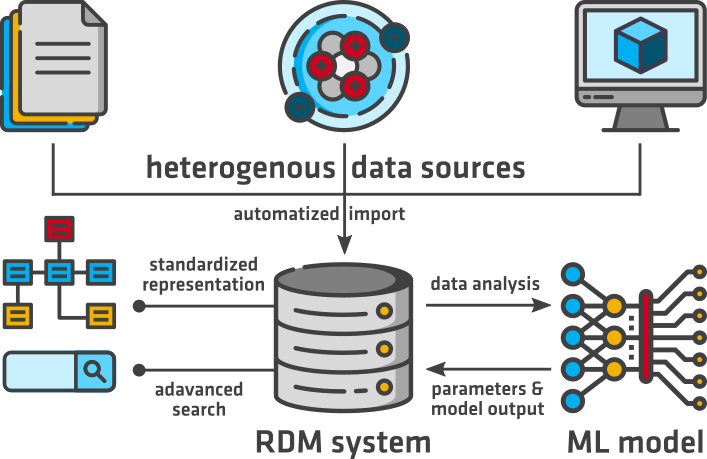
At BAM, we aim to facilitate the application of ML methods by integrating appropriate research data management (RDM) strategies in the whole research process from the creation of a materials dataset to its preprocessing and integration with further data in an ML model to its publication in a scientific repository. We aim to develop services and standards that empower researchers to describe, manage and track the provenance of research data from heterogeneous sources in a central RDM system in a standardized and interoperable manner in line with the FAIR principles for scientific data management [1]. The parameters and results of an ML model will be linked with the datasets used for training or testing, thus providing the basis for seamless tracking of data lineage and contributing to the transparency of ML applications in MSE.The desired functionality of an RDM system for ML includes i.a. the following features:
- automated import (where necessary including quality control) of data and metadata from heterogeneous sources
- standardized representation of domain-specific features
- advanced metadata search capabilities
- integration with computational tools and workflows for statistical data analysis and ML via APIs
- automated feedback of parameters and output of the ML model into the RDM system
- export of data (including source code) and associated metadata to public repositories