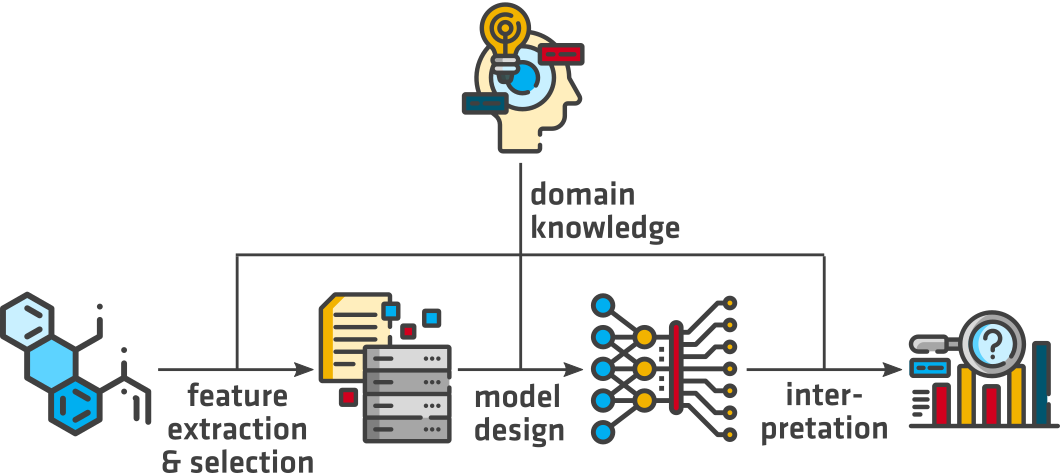
Motivation
The representation of materials as data, i.e., a numerical feature vector, is not straight-forward and requires
decisions on the captured properties (e.g., mechanical properties, composition and crystal structure) and their
encryption (e.g., human-readable). Applied on large data sets a representation that uses little-to-no domain
knowledge might perform as well as an informed
feature selection. However, for
scarce data, which
are
common in
materials science, the featurization has significant impact on the prediction performance of machine learning
(ML) models [1]. Similarly, the
model design becomes more important with limited data and should consider
aspects of overfitting and
model interpretability.
Objectives
At BAM we aim to use the in-house expertise on material compositions, structures and properties to improve data
driven materials science and engineering. There is no single method of building in domain knowledge in ML
approaches. Our benefit is the close collaboration between material and data scientists, that enables the
development of efficient and creative solutions, e.g., to
- derive domain specific feature selections, such as composition-based feature vectors, to improve
the
prediction performance of ML models
- develop human-readable feature formats that increase interpretability and may help to
provide physical
and chemical insights
- improve the model performance by capturing known correlations and analytical relations, e.g., via
transfer learning
- complement time and cost intensive experimental data with simulated data, which are based on
physical
principles
References
[1] Murdock, R. J., Kauwe, S. K., Wang, A. Y.-T. & Sparks, T. D. “Is Domain Knowledge Necessary for Machine
Learning Materials Properties?” Integrating Materials and Manufacturing Innovation 9, 221–227 (2020).