Activities
Research directions, methods, and projects we’re working on.
Prediction of Materials Properties
The design of new materials and the optimization of their properties is central to overcome current global challenges [1]. Our goal at BAM is to discover new materials that make technology more functional, secure, and sustainable. However, the feasible space of materials is far too large to explore it experimentally. Simulations derived from first principles, such as Density Functional Theory (DFT), allow to compute materials properties without the need of expensive and time-consuming experimental synthesis. Although the computational cost of simulations is still far too high for an efficient exploration of the materials space, databases containing simulation results of numerous material types are continuously growing.Machine learning (ML) models trained on existing databases are used as surrogate models in high-throughput screening to guide the search for new materials. They are computationally more efficient than simulations and allow to obtain fast property estimations by which the set of candidates can be narrowed down. As opposed to simulations, which require the exact structure of materials, statistical and ML methods are more flexible and allow to model both the structure-property and composition-property relationships. Working merely with the composition of materials is in many cases preferred, because it eliminates the need to first identify the optimal structure.
Objectives
Although theories of quantum-mechanical systems derived from first principles implicitly contain information about structure-property and composition-property relationships, we do not gain a deeper understanding of these relationships by producing ever larger databases. In the spirit of the saying, “the whole is simpler than the sum of its parts” (J. W. Gibbs), we develop statistical and ML methods to search databases for predictive patterns.These patterns can take on many forms, for instance:
- graphs
- descriptors derived from atomistic structures
- compositional patterns
References
[1] https://www.bam.de/Navigation/DE/Themen/Material/Materialdesign/materialdesign.htmlMachine Learning based PDE Solutions in Materials Science
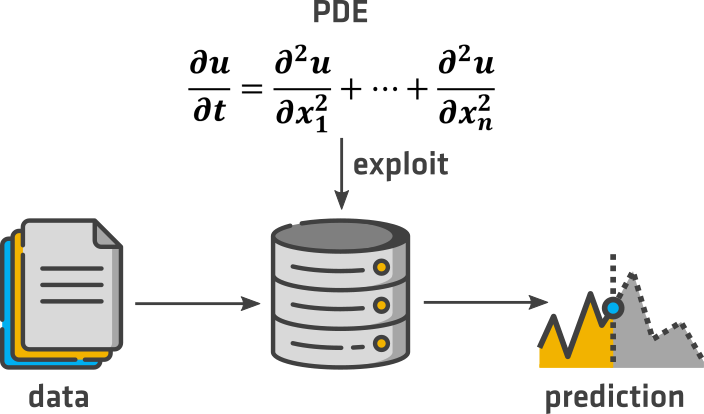
Objectives
We aim to develop ML-based PDE solvers that speed up the solution of PDEs that appear in materials science problems. The speed up will allow us to solve downstream tasks such as fitting the model parameters to observed data.- ML-based PDE solvers allow us to incorporate more laws of physics into ML approaches and hence to reduce the amount of required training data.
- The speed-up allows us to work with the models more interactively, and
- to solve downstream tasks such as fitting the model parameters to observed data.
Domain Specific Machine Learning for Materials Science & Engineering
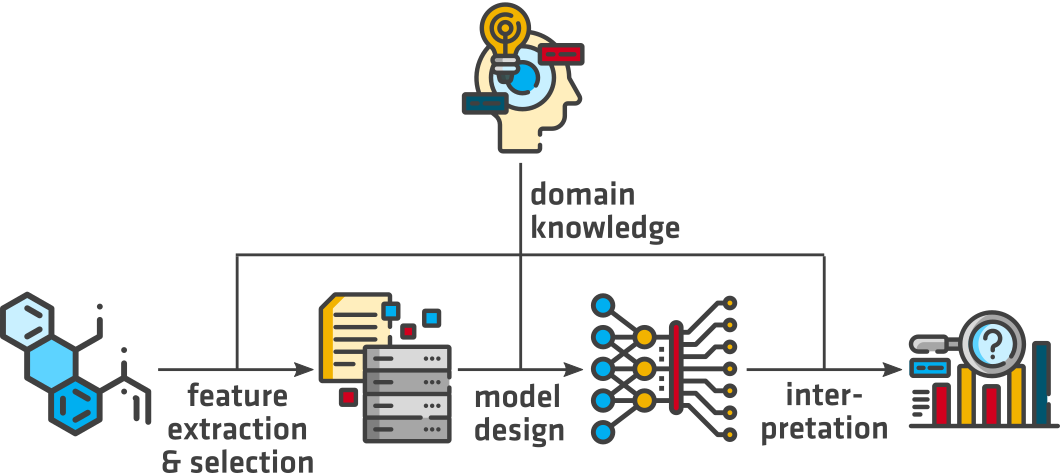
Objectives
At BAM we aim to use the in-house expertise on material compositions, structures and properties to improve data driven materials science and engineering. There is no single method of building in domain knowledge in ML approaches. Our benefit is the close collaboration between material and data scientists, that enables the development of efficient and creative solutions, e.g., to- derive domain specific feature selections, such as composition-based feature vectors, to improve the prediction performance of ML models
- develop human-readable feature formats that increase interpretability and may help to provide physical and chemical insights
- improve the model performance by capturing known correlations and analytical relations, e.g., via transfer learning
- complement time and cost intensive experimental data with simulated data, which are based on physical principles
References
[1] Murdock, R. J., Kauwe, S. K., Wang, A. Y.-T. & Sparks, T. D. “Is Domain Knowledge Necessary for Machine Learning Materials Properties?” Integrating Materials and Manufacturing Innovation 9, 221–227 (2020).Efficient Sampling in Materials Science
In materials science, the generation of data sets that are suitable for machine learning (ML) applications is usually expensive. Generally, the data space is complex and requires many samples to be represented. For this purpose, not only the number of samples matters, but also the information content of each sample. Active learning methods are used for simultaneous learning and data acquisition simultaneously learn relations and acquire the data points. Active learning algorithms know what they do not know and identify the data points that have the highest potential for increasing the knowledge.Objectives
We aim to develop active learning approaches. The challenge that we face is the high dimension of the material space.- Active Learning allows us to reduce the number of experiments that we spend in order to find optimal settings.
- Active Learning helps us to automatize the experimental process.
A Holistic Fire Management Ecosystem for Prevention, Detection and Restoration of Environmental Disasters
Motivation
Wildfires are a severe threat across Europe, causing significant environmental and economic damage. They are becoming more intense and widespread as a result of climate change, particular forestry practices, ecosystem deterioration, and rural depopulation. BAM is member of a large-scale EU Green Deal project with 47 partners from 13 European countries and Taiwan, that covers all three stages of fire management – namely prevention, detection and restoration. A holistic Fire Management Ecosystem is key to implement effective and sustainable actions in the fight against wildfires.Objectives
In the EU project [1] BAM eScience contributes to the work packages ‘prevention and preparedness’ and ‘detection and response’ on detecting emerging critical situations and forecasting fire and smoke propagation with Machine Learning (ML) techniques. A context-aware detection of emerging fire-related situations will be based on real-time and heterogenous sensor data that capture e.g., weather and soil conditions. They may additionally include factors like structural causes rooted in land and urban planning, human activities in the vicinity of forests and cultural traditions that are typically not considered by current systems. A real-time fire and smoke propagation forecasting system will be developed to support timely decisions and improve firefighting tactics. Physical fire and smoke spread models, which provide accurate predictions, are computationally too expensive for real-time forecasting and mitigation strategies. We will translate physical models into ML models for accurate real-time predictions. These models incorporate knowledge about vegetation and environmental conditions and will incorporate experimental data from experiments performed at BAM.References
[1] https://treeads-project.eu/https://twitter.com/TreeadsH2020
https://www.linkedin.com/company/treeads-h2020/
Research Data Management
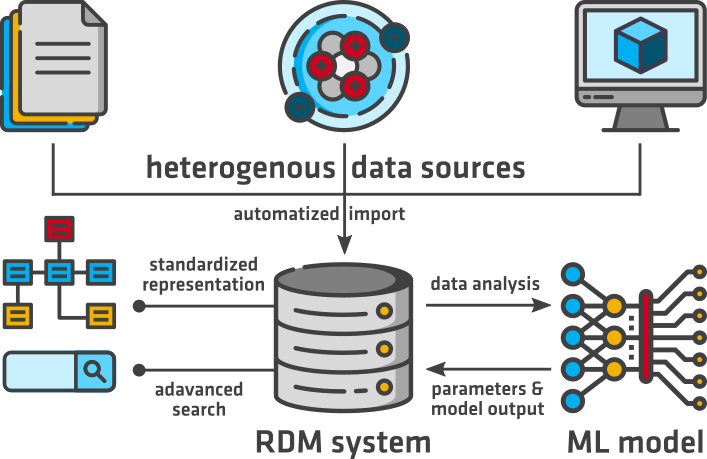
The systematic extraction of informative features from raw data to use as input for an ML algorithm (feature engineering) requires consistent and standardized data formats that are described with rich metadata. Accordingly, the acquisition, preprocessing, and quality control of data (often combined from heterogeneous data sources) is both a critical and a time-intensive step in building an ML model, particularly in the MSE domain. The high cost and time required for, e.g., the experimental synthesis of new materials and the characterization and optimization of their properties often precludes the generation of a sufficiently large volume of new data by single research groups or even institutions, highlighting the need for the development of common data standards and infrastructures for the sharing of MSE datasets.
Objectives
At BAM, we aim to facilitate the application of ML methods by integrating appropriate research data management (RDM) strategies in the whole research process from the creation of a materials dataset to its preprocessing and integration with further data in an ML model to its publication in a scientific repository. We aim to develop services and standards that empower researchers to describe, manage and track the provenance of research data from heterogeneous sources in a central RDM system in a standardized and interoperable manner in line with the FAIR principles for scientific data management [1]. The parameters and results of an ML model will be linked with the datasets used for training or testing, thus providing the basis for seamless tracking of data lineage and contributing to the transparency of ML applications in MSE.The desired functionality of an RDM system for ML includes i.a. the following features:
- automated import (where necessary including quality control) of data and metadata from heterogeneous sources
- standardized representation of domain-specific features
- advanced metadata search capabilities
- integration with computational tools and workflows for statistical data analysis and ML via APIs
- automated feedback of parameters and output of the ML model into the RDM system
- export of data (including source code) and associated metadata to public repositories